


Stephen Hawking, el físico británico, hablaba gracias a un sensor en sus gafas que detectaba el movimiento de su mejilla. Así seleccionaba letras en una pantalla. Cuando terminaba una frase, su computadora la convertía en voz con un sintetizador. Esa fue la voz robótica que todos recordamos.
Desde la muerte del Prof. Hawking en 2018, la tecnología ha avanzado muchísimo. Hoy existen dispositivos que pueden leer la actividad del cerebro y convertirla directamente en texto o incluso en sonido.
El problema es que esos sistemas tardaban bastante en funcionar y, además, solo entendían palabras predefinidas. No captaban cosas como el tono o la entonación.
El nuevo trabajo
Pero un equipo de científicos de la Universidad de California en Davis ha dado un gran paso. Han creado una prótesis cerebral que convierte señales del cerebro directamente en sonidos. Los detalles han sido publicados en Nature.
La idea es que personas con parálisis puedan comunicarse con fluidez, usando su ritmo y expresando emociones con la voz, como cualquiera de nosotros.
Lograr esto fue todo un reto. Los sistemas anteriores solo transformaban pensamientos en texto, no en sonido real. Por ejemplo, un grupo de Stanford logró traducir pensamientos a texto, pero se equivocaba en una de cada cuatro palabras. No era suficiente.
Luego, en 2024, el equipo de Davis mejoró esa cifra a un 97.5 % de aciertos. Casi perfecto. Pero igual, usar texto tiene límites. No puedes hacer interjecciones, cantar, o usar palabras raras o en otros idiomas. La voz tiene una riqueza que el texto no alcanza.
Además, todo ese proceso tenía una demora molesta. El paciente pensaba algo, lo escribía mentalmente, y solo después de varios segundos se escuchaba la frase. Incluso si el sistema tenía un diccionario enorme, fallaba cuando uno decía un nombre raro o algo fuera de lo común.
La prueba
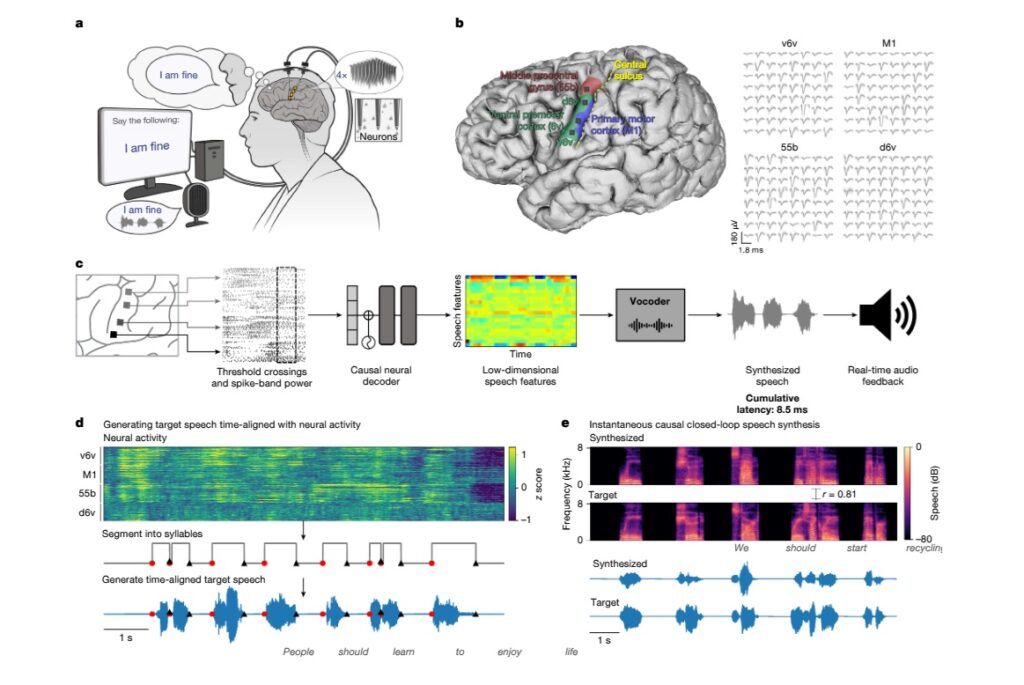
Por eso, la nueva prótesis salta el paso del texto y convierte directamente las señales cerebrales en sonido, en tiempo real. El paciente del estudio se llama T15 (para proteger su identidad) y tiene 46 años. Padece ELA y casi no puede moverse ni hablar claramente. Antes se comunicaba moviendo el cursor con la cabeza. Era lento, complicado y muy limitado.
Para esta nueva tecnología, los médicos le implantaron 256 microelectrodos en una zona del cerebro que controla los músculos de la voz. Con esos electrodos, registraron señales neuronales de altísima precisión. Luego, una inteligencia artificial las descifró y extrajo características del habla, como el tono o la sonoridad.
Finalmente, otro algoritmo llamado vocoder usó esa información para reconstruir la voz de T15, tal como sonaba antes de perderla.
Lo impresionante es que todo el proceso ocurre casi al instante. La demora es de solo unos 10 milisegundos. Esto marca un paso enorme hacia una voz digital que nace directamente del pensamiento. Algo que parecía ciencia ficción, hoy es casi real.